前言:
在周末抽空看了一天的爬虫教程,对于静态的网站能利用正则表达等进行简单的爬取,这次主要把重心放到爬取动态页面上,同时对于文件的处理也略有思考,所以在此记录一下
题目:
爬取上交所每日股票情况的数据,将表格中的原始数据进行处理如图,方便转成DataFrame使用

背景知识补充:
JSON
概述
JSON是一种取代XML的数据结构,和xml相比,它更小巧但描述能力却不差,由于它的小巧所以网络传输数据将减少更多流量从而加快速度。
语法规范
JSON 的语法规则十分简单,可称得上“优雅完美”,总结起来有:
数组(Array)用方括号(“[]”)表示。
对象(Object)用大括号(”{}”)表示。
名称/值对(name/value)组合成数组和对象。
名称(name)置于双引号中,值(value)有字符串、数值、布尔值、null、对象和数组。
并列的数据之间用逗号(“,”)分隔
实例
JSON 数据的书写格式是:名称/值对。
名称/值对组合中的名称写在前面(在双引号中),值对写在后面,中间用冒号隔开,
其中 值 可以是:数字(整数或浮点数)、字符串(在双引号中)、布尔值(true或false)、数组(在方括号中)、对象(在花括号中)、null
varjson= {“password”:123456,”name”:”myname”,”Booleans”:true,”Array”:[x,y,z],”object”:{}}
或者是嵌套使用
与python字典的互相转换
用到的库
json
用到的方法
dumps():将字典转换为JSON格式的字符串
loads():将JSON格式的字符串转化为字典
dump():将字典转换为JSON格式的字符串,并将转化后的结果写入文件
load():从文件读取JSON格式的字符串,并将其转化为字典
实例
1
2
3
4
5
6
7
8
9
10import json
#json 转python字典
j='{"city":"北京","ss":"天京"}'
p=json.loads(j)
print(type(p))
#字典转json
d={"city":"北京","ss":"天京"}
ss=json.dumps(d,ensure_ascii=False) #不转成Ascii码
print(ss)
思路:
首先观察我们需要的数据位置,发现并不在起初的静态页面上
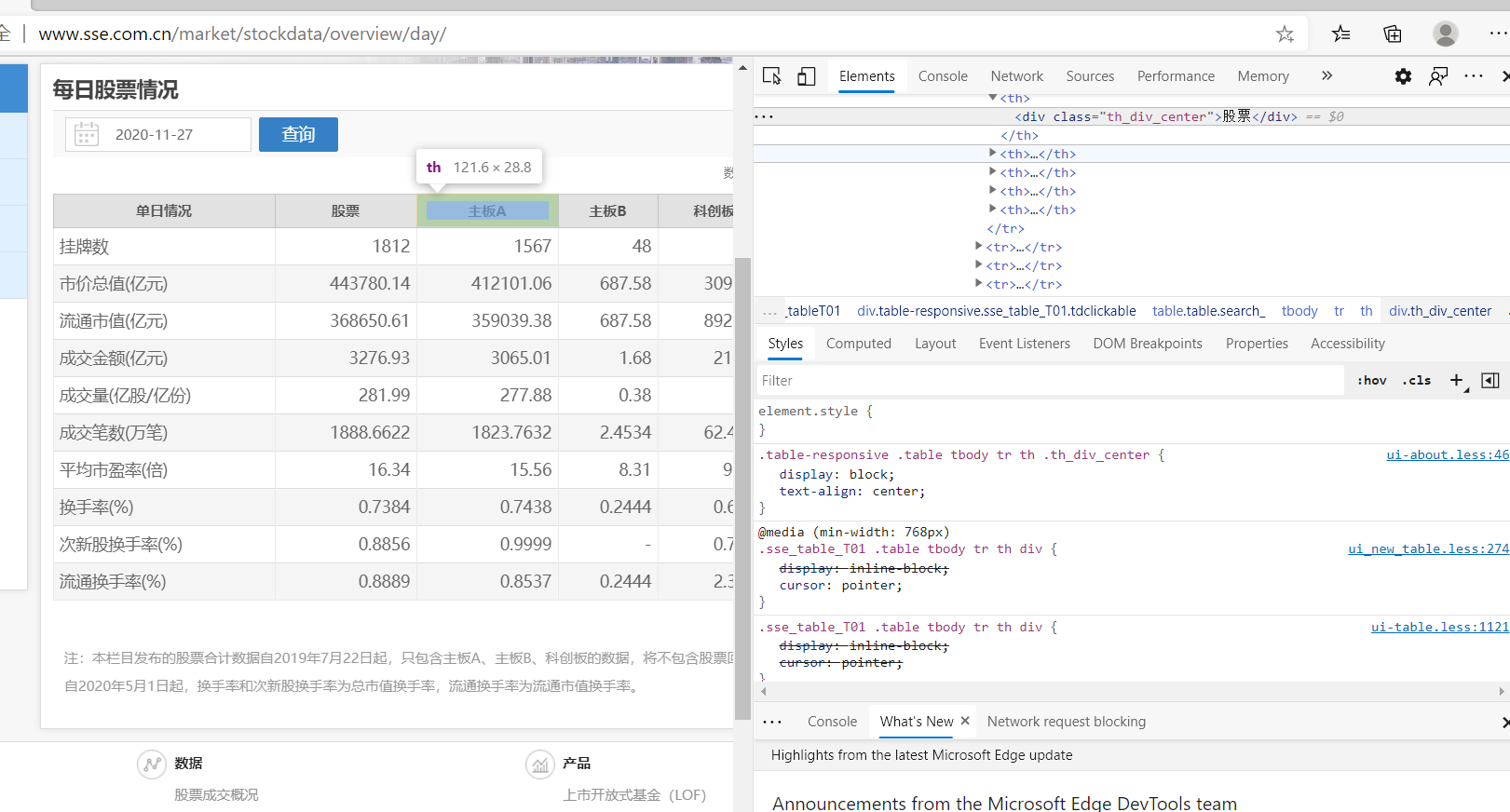
经过一番查找,咱们总算是找到数据存在的位置
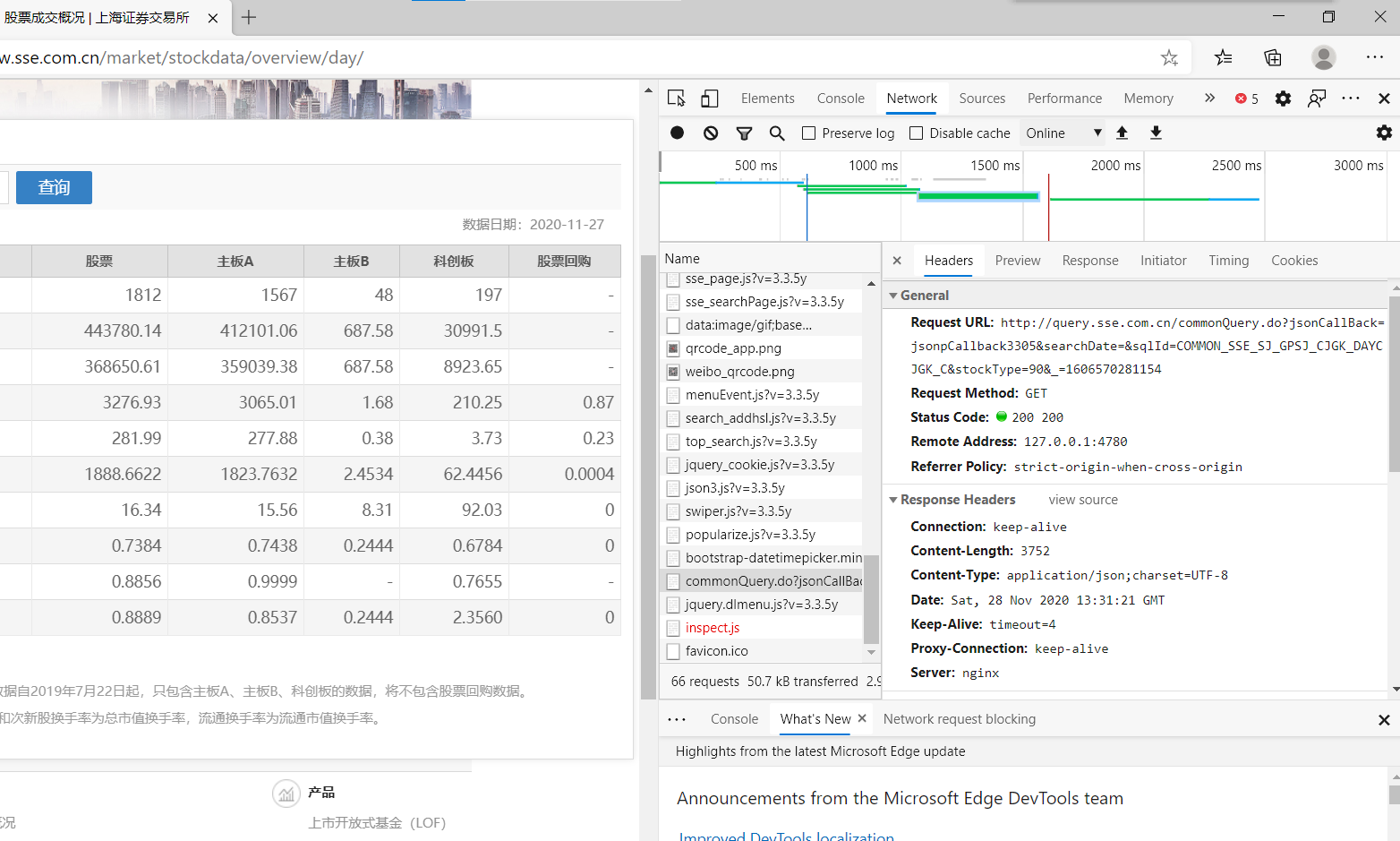
好,那么接下来我们观察数据的格式,发现比咱们期望得到的json格式多了个jsoncallback,这里考虑用strip()函数去除不符合json格式的字符,这样剩下来的就是json格式的文件,便于我们转换成python字典
代码编写:
声明
在编写代码之前加一串声明头,是一个不错的好习惯
1 | # -*- codeing = utf-8 -*- |
导入
本次编码由于不需要保存和正则查找,所以只需要导入json以及requests就行
主函数编写
思路
先爬取网页的数据,也就是咱们把上面找到需要的网站数据给爬下来
接着将爬取下来的数据保存在一个新的字典中
最后print出来检测一下
代码
1 | def main(): |
网站请求函数编写
思路
先编写headers(否则会被网站识别是爬虫而拒绝访问,尤其要注意添加referer,否则无法正常访问)
其次调用requests库
最后将数据以text格式保存在data中
代码
1 | def askurl(url): |
数据处理函数编写
思路
首先我们需要将data内容转换为json格式
其次将json文档转换为python字典
接着将字典中需要的字段转换为中文
然后挑选出我们需要的字段形成字典(创建一个需要字段的字典进行遍历)
最后整合一下就好啦
源码
1 | def processdata(url): |
最终代码展示
1 | # -*- codeing = utf-8 -*- |
最终效果展示

